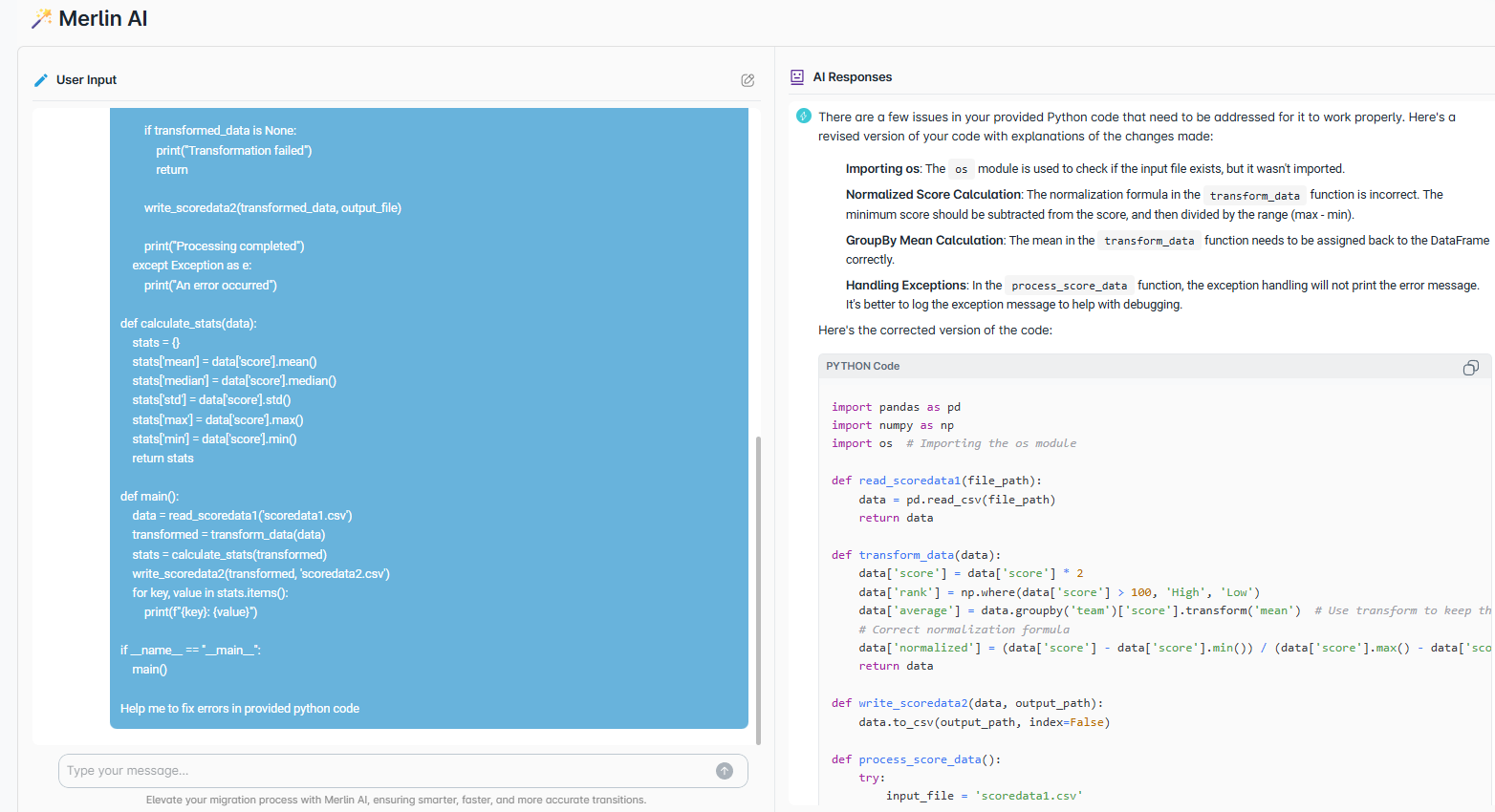
Code Analysis
Assess thousands of PowerCenter mappings and IDMC CDI tasks, map complexity across transformations and workflows, and flag readiness. Get clear scope, a prioritized plan, safer cutovers, and faster production.

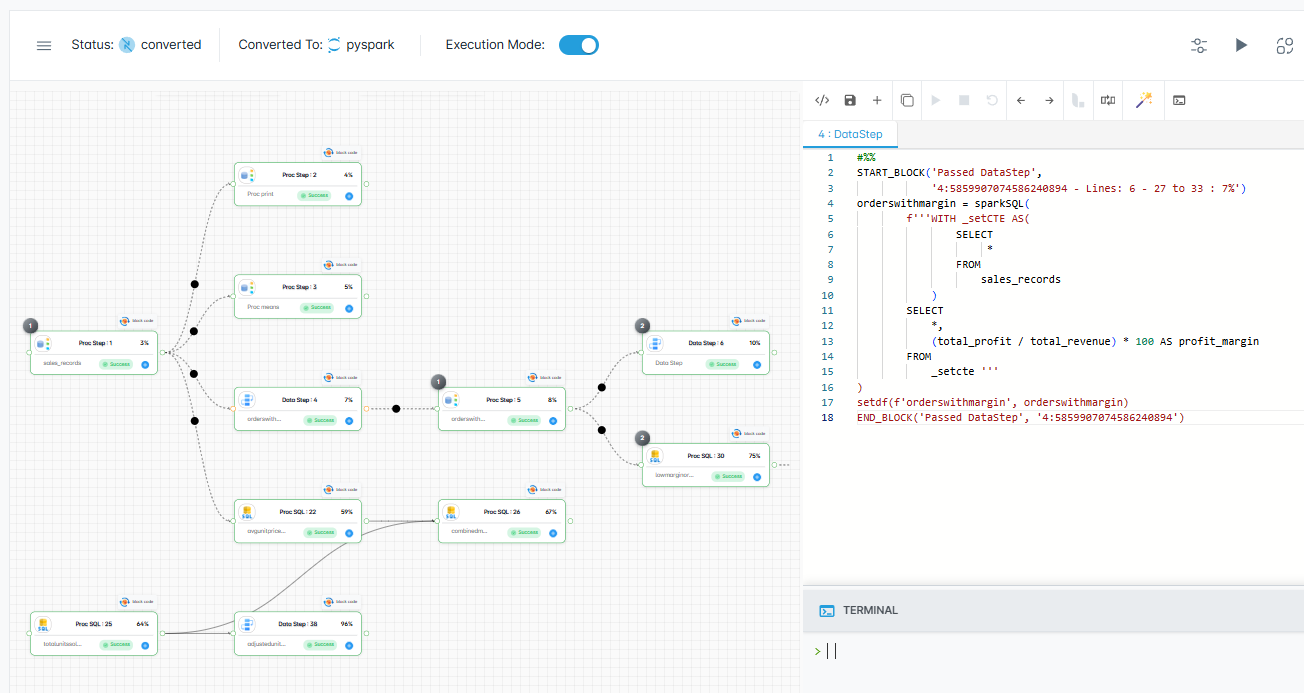
Visual Lineage
Visualize mappings, sessions, and pipelines across PowerCenter and IDMC to see sources, joins, and SQL pushdown. Speeds impact checks, lowers migration risk, supports audits, and proves outputs match.

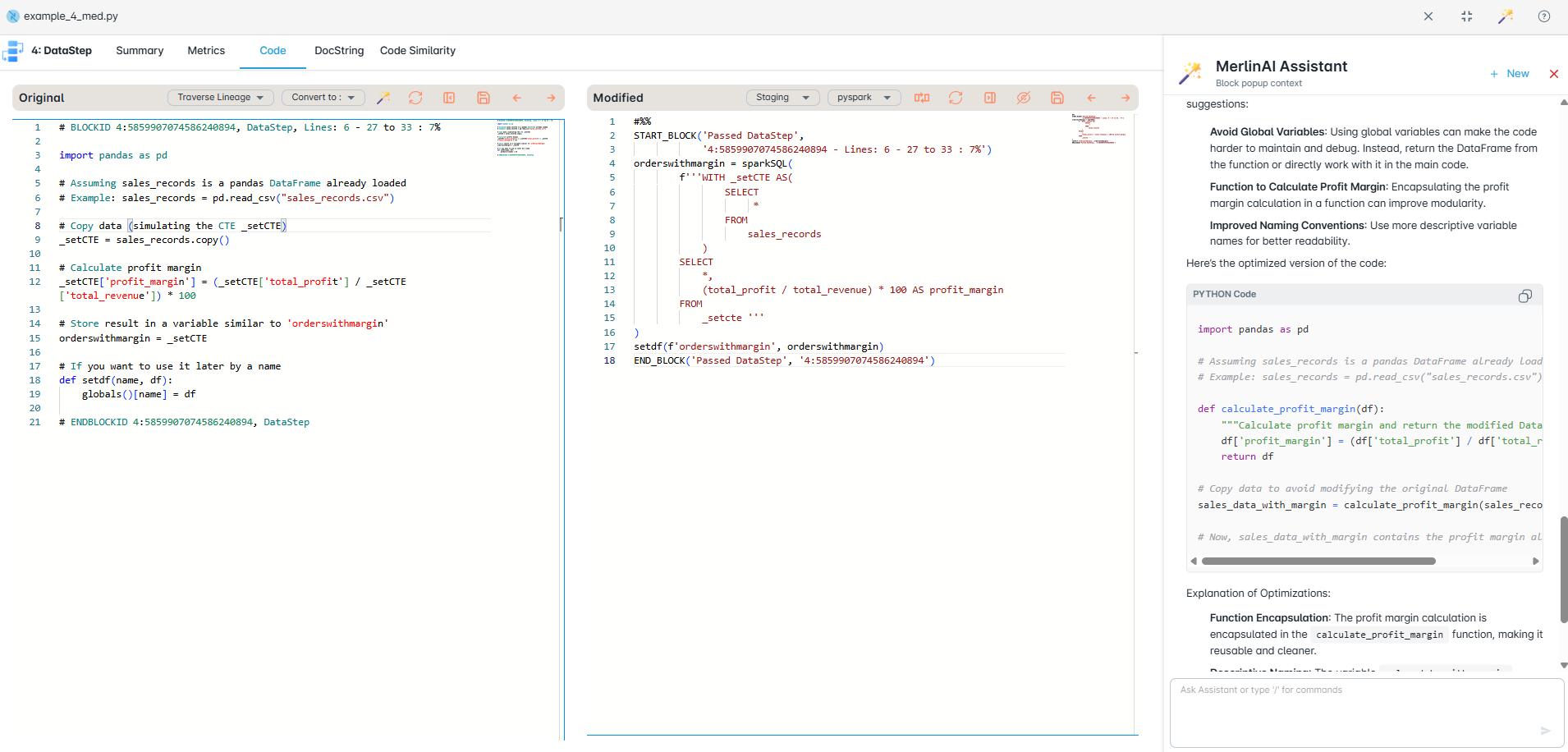
Code Conversion
Convert Informatica mappings and taskflows into Python, PySpark, Snowpark, or SQL with matched outputs — including expression logic and SQL overrides where appropriate. Modernize faster, keep logic intact, and avoid risky rewrites.

Data Mapper
Automatically map legacy schemas to Snowflake or Databricks with clear mappings. Cut migration risk, enforce naming and data types, and get audit-ready visibility.

Auto Docs
Automatic documentation captures your Informatica mappings and the new target code, detailing transformations, mapplets, parameters, and dependencies for clear traceability.

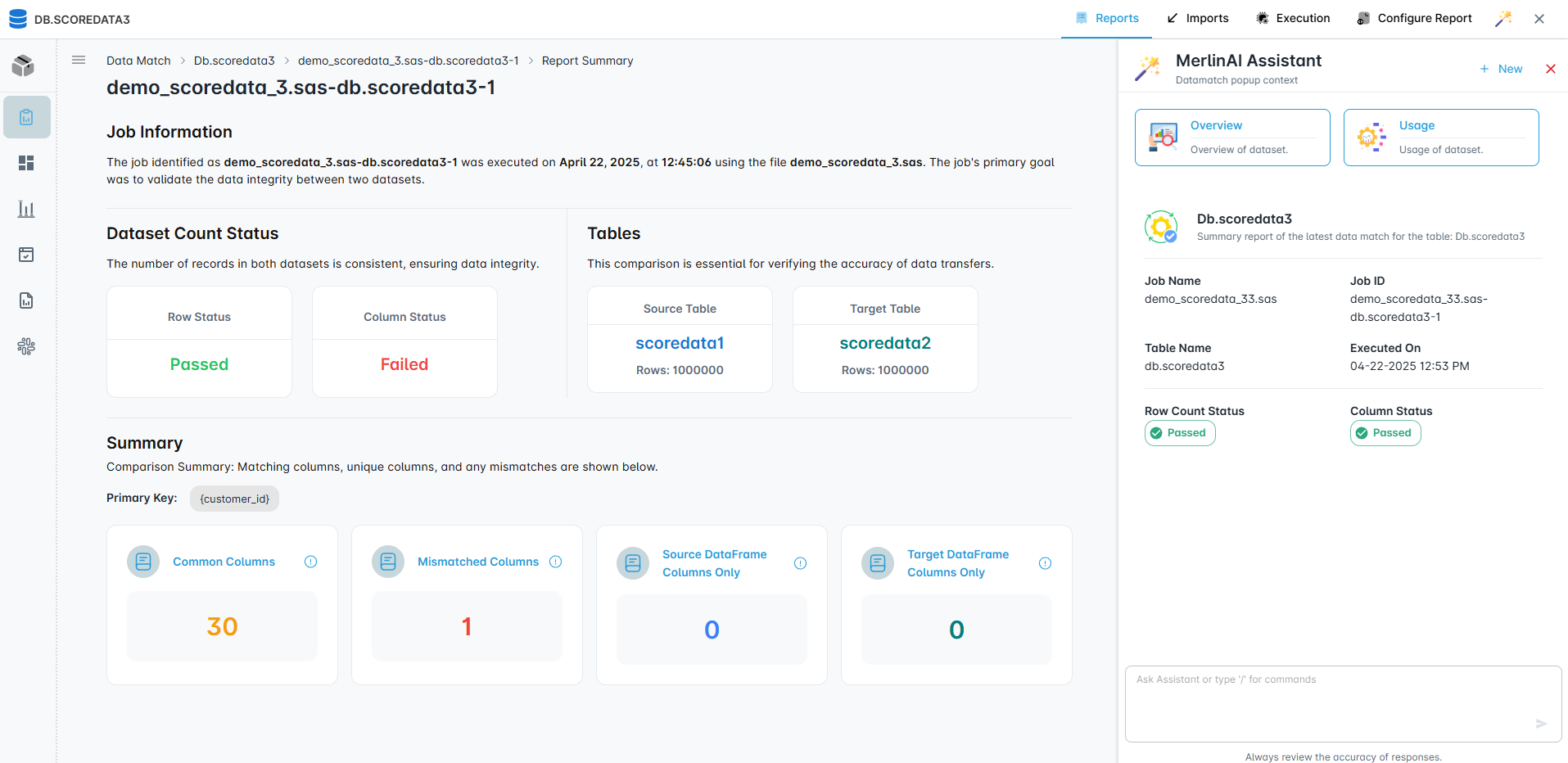
Data Matching
Compares source and target outputs at scale using configurable keys and rules. Flags mismatches, duplicates, and gaps with actionable reports for fast fixes.